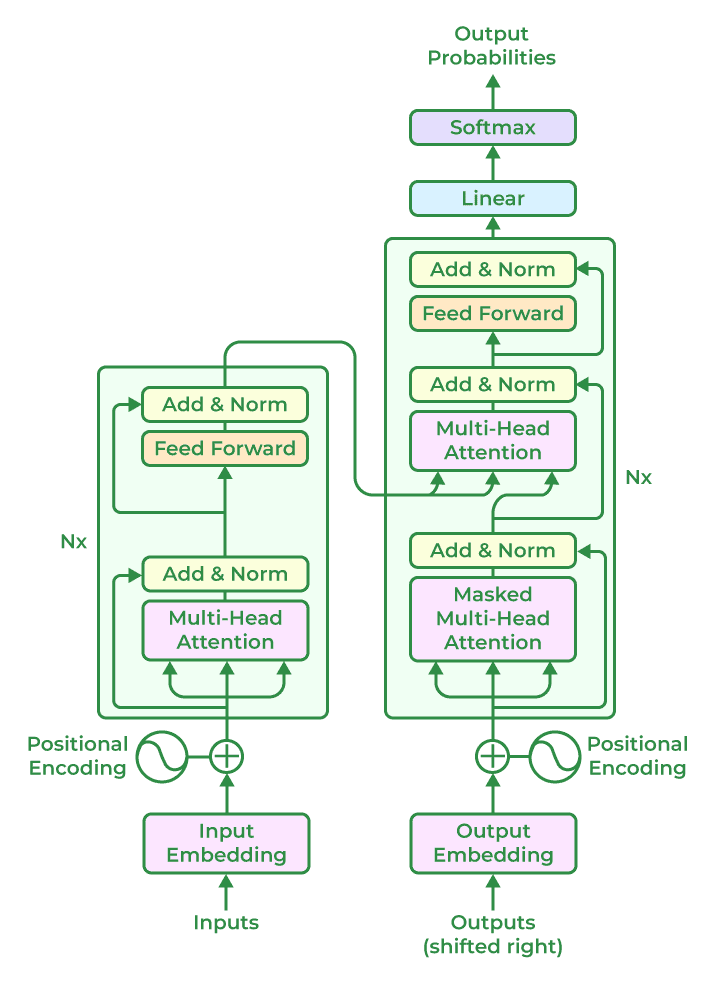
How LLMs Work
- Input Embedding: Converts text tokens into dense vector representations for processing.
- Positional Encoding: Adds positional information to embeddings to provide sequence context.
- Transformer Encoder: - Multi-Head Attention: Captures relationships between tokens in the input sequence. - Add & Norm: Ensures stability during processing. - Feed Forward: Applies a fully connected layer to transform the data.
- Transformer Decoder: - Masked Multi-Head Attention: Focuses on prior tokens during training for causal prediction. - Multi-Head Attention: Combines context from the encoder and decoder layers. - Add & Norm & Feed Forward: Enhances stability and feature extraction.
- Output Layer: Maps decoder outputs to probabilities for each token using a Softmax function.
- Applications: Powers tasks like text generation, translation, summarization, and conversational AI.
LLM Code Example
Here's how we can define the layers of a simplified Large Language Model:
import tensorflow as tf
from tensorflow.keras import layers
model = tf.keras.Sequential([
layers.Input(shape=(None, 512)), # Input Layer (sequence length = None, features = 512)
layers.MultiHeadAttention(num_heads=8, key_dim=64), # Self-Attention Layer
layers.Dense(2048, activation="relu"), # Feedforward Network Layer 1
layers.Dense(512, activation="relu"), # Feedforward Network Layer 2
layers.Dense(10000, activation="softmax") # Output Layer (vocabulary size = 10,000)
])