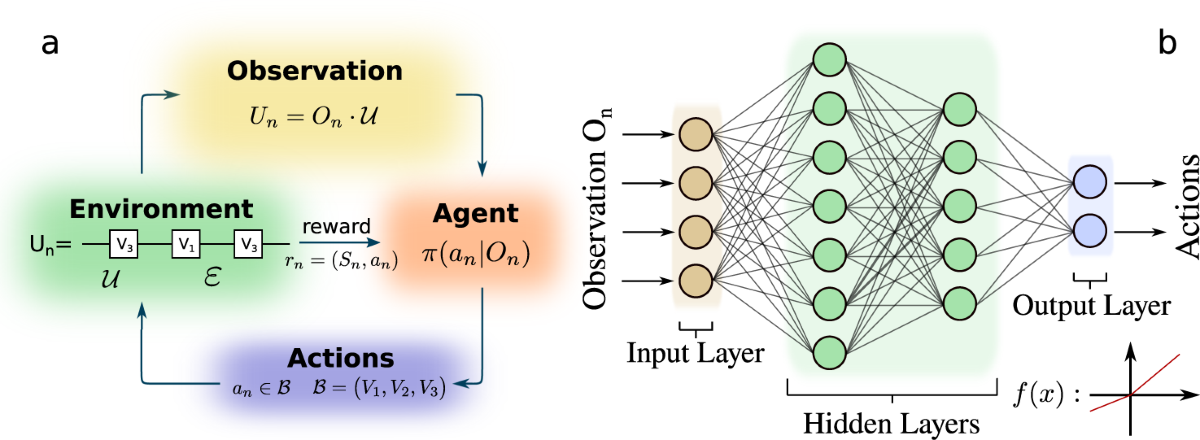
How RL Works
- Agent: The decision-maker that interacts with the environment by choosing actions based on its policy.
- Environment: The system or world in which the agent operates. Provides observations and rewards based on the agent’s actions.
- Observation: The agent observes the current state of the environment to gather information.
- Actions: Based on observations, the agent selects an action from a set of possible actions to influence the environment.
- Rewards: The environment provides feedback (rewards or penalties) to evaluate the effectiveness of the agent’s actions.
- Policy: A strategy (\(\pi\)) that defines how the agent selects actions based on the current state or observation.
- Objective: The agent learns to maximize the cumulative reward by improving its policy over time through trial and error.
- Applications: - Robotics (e.g., navigation and control). - Game AI (e.g., mastering chess or video games). - Finance (e.g., portfolio optimization). - Autonomous systems (e.g., traffic control).
Deep Reinforcement Learning (DQN) Code Example
Here's how we can define the layers of a Deep Q-Network (DQN):
import tensorflow as tf
from tensorflow.keras import layers
def build_dqn(state_shape, num_actions):
"""
Deep Q-Network (DQN) Model
:param state_shape: Shape of the input state (e.g., (84, 84, 4) for Atari games)
:param num_actions: Number of possible actions in the environment
"""
model = tf.keras.Sequential([
layers.Input(shape=state_shape), # Input Layer (state)
layers.Conv2D(32, kernel_size=8, strides=4, activation="relu"), # Convolutional Layer 1
layers.Conv2D(64, kernel_size=4, strides=2, activation="relu"), # Convolutional Layer 2
layers.Conv2D(64, kernel_size=3, strides=1, activation="relu"), # Convolutional Layer 3
layers.Flatten(), # Flatten layer to convert 3D feature maps into 1D
layers.Dense(512, activation="relu"), # Fully Connected Layer
layers.Dense(num_actions, activation="linear") # Output Layer (Q-values for each action)
])
return model
# Instantiate the DQN Model
state_shape = (84, 84, 4) # Example: stacked 4 frames of an 84x84 grayscale input
num_actions = 6 # Example: 6 possible actions in the environment
dqn_model = build_dqn(state_shape, num_actions)